SQL (Structured Query Language) es una de las herramientas más poderosas y utilizadas en el análisis de datos. Sin embargo, incluso quienes ya tienen experiencia cometen errores que pueden afectar la precisión, eficiencia o claridad de sus consultas.
En este artículo, exploramos los errores más comunes al trabajar con SQL y cómo puedes evitarlos con buenas prácticas y atención al detalle.
👇🏻👇🏻👇🏻
No entender la estructura de la base de datos
Uno de los errores más frecuentes es comenzar a escribir consultas sin tener claridad sobre cómo están relacionadas las tablas, qué campos existen o cuáles son claves primarias y foráneas.
Ejemplo del error:
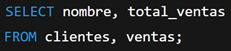
Esto genera una unión cruzada, lo que puede devolver millones de combinaciones incorrectas.
Cómo evitarlo:
- Revisa el diagrama entidad-relación o el esquema de la base de datos.
- Usa JOIN explícitos.
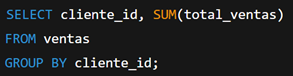
Olvidar agrupar al usar funciones de agregación
Usar funciones como SUM(), AVG() o COUNT() sin GROUP BY suele producir errores o resultados inesperados.
Ejemplo del error:

Este código genera error si cliente_id no está en una cláusula GROUP BY.
Cómo evitarlo:
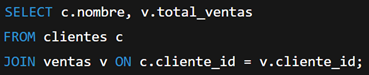
- Asegúrate de agrupar por los campos no agregados:
Usar SELECT * en ambientes productivos
Aunque usar SELECT * parece cómodo, puede traer problemas de rendimiento, seguridad o compatibilidad si la estructura de la tabla cambia.
Cómo evitarlo:
- Especifica solo las columnas necesarias:
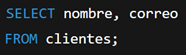
Esto también mejora la legibilidad y reduce la carga sobre la red y el sistema.
No filtrar correctamente con WHERE
A veces olvidamos agregar condiciones clave o usamos mal los operadores de comparación.
Ejemplo del error:

Este filtro probablemente no devuelva nada porque está comparando una fecha con un valor de año-mes incompleto.
Cómo evitarlo:
- Usa funciones de fecha o rangos adecuados:

Confundir los tipos de JOIN
Elegir mal el tipo de JOIN puede excluir o duplicar datos sin darte cuenta.
Error común:
Usar INNER JOIN cuando se necesitan también los datos sin coincidencia.
Cómo evitarlo:
- Asegúrate de entender la diferencia entre:
- INNER JOIN: Solo coincidencias en ambas tablas.
- LEFT JOIN: Todos los registros de la tabla izquierda, y coincidencias de la derecha.
- RIGHT JOIN: Lo contrario.
- FULL JOIN: Todos los registros de ambas tablas (cuando está soportado).
No limpiar los datos antes de analizarlos
SQL no impide que analices datos incompletos o mal estructurados, pero eso puede afectar tu análisis.
Ejemplo del error:
No considerar que NULL no se comporta como 0 o como una cadena vacía.
Cómo evitarlo:
- Usa filtros adecuados:

- O funciones como COALESCE para sustituir valores nulos:

No usar alias o usarlos mal
Alias poco claros o inexistentes hacen que las consultas sean difíciles de leer.
Mal ejemplo:
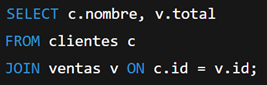
Buen ejemplo:

Usar HAVING en lugar de WHERE (o viceversa)
WHERE filtra antes de la agregación; HAVING después.
Ejemplo incorrecto:
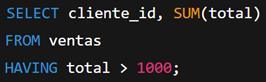
Esto falla porque total no existe como columna.
Corrección:
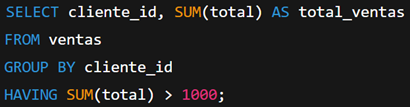
No optimizar las consultas para bases grandes
Consultas mal estructuradas pueden tardar minutos o más en ejecutarse.
Cómo evitarlo:
- Agrega índices en campos que se usan en joins o filtros.
- Evita subconsultas innecesarias.
- Usa vistas o tablas intermedias si hay muchos cálculos.
Ignorar los mensajes de error o advertencia
Muchos errores de SQL vienen con mensajes útiles que son ignorados o malinterpretados.
Cómo evitarlo:
- Lee con atención los errores, suelen indicar qué parte de la consulta falló.
- Usa un entorno como SSMS, DBeaver, MySQL Workbench o Azure Data Studio que te ayude con sugerencias.
SQL es una herramienta esencial, pero dominarla implica más que aprender la sintaxis. Evitar estos errores comunes no solo mejora tus resultados, sino también tu rendimiento como analista de datos. Recuerda siempre revisar tus consultas, probar con pequeños fragmentos y validar los resultados que obtienes.
¿Quieres seguir mejorando tu SQL?
Practica desde nuestra academia en
www.datdata.com/sql
Ver esta publicación en Instagram
👉 También te recomendamos nuestros artículos de Visualización de Datos y Cómo entender SQL cuando ya sabes Power BI
🖱️ Visita nuestro canal de YouTube para aprender Power BI, y síguenos en Instagram , Linkedin y Facebook para aprender en tus tiempos libres.
Te vemos en otro artículo 💪


