Las 10 funciones más utilizadas de SQL para análisis de datos (con ejemplos paso a paso)
15 de octubre de 2025
Si estás aprendiendo SQL para análisis de datos, seguramente ya sabes hacer consultas básicas con SELECT, FROM o WHERE. Pero llega un punto en el que necesitas algo más que filtrar o mostrar información: necesitas transformarla, resumirla y encontrar patrones. Ahí es donde entran las funciones de SQL, que te permiten calcular totales, promedios, contar registros, comparar valores o incluso crear nuevas columnas con condiciones personalizadas.
En este artículo conocerás las 10 funciones más utilizadas de SQL para análisis de datos, explicadas con ejemplos prácticos y paso a paso.
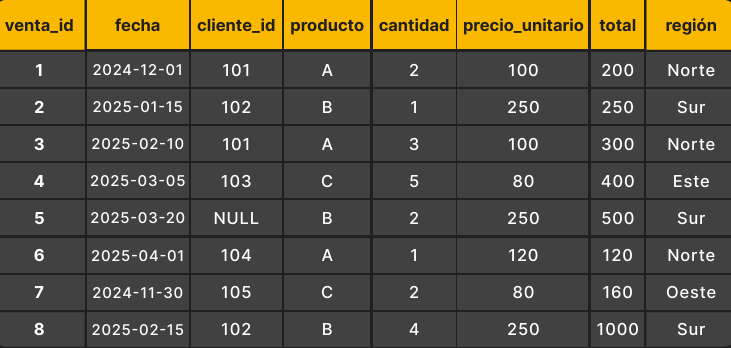
No necesitas una base de datos compleja para practicar —usaremos un mini-dataset que te ayudará a entender cómo funcionan las funciones más importantes, desde COUNT() y SUM() hasta expresiones más potentes como ROW_NUMBER(). Dataset ejemplo:
COUNT() — contar filas y valores distintos
Descripción rápida: cuenta filas; puede contar todas las filas COUNT(*), o sólo las no nulas de una columna COUNT(col), o valores únicos COUNT(DISTINCT col).
Ejemplo simple — número total de ventas
Paso a paso:
COUNT(*) recorre todas las filas de ventas.
Con el dataset de ejemplo devuelve 8.
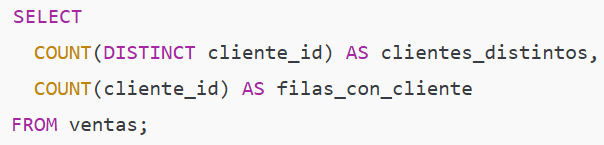
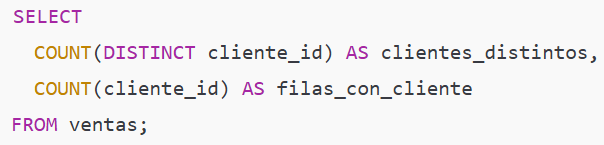
Ejemplo intermedio — clientes distintos y clientes no nulos
Qué hace y por qué importa:
COUNT(DISTINCT cliente_id) cuenta clientes únicos (excluye NULL). Resultado: 5 (101,102,103,104,105).
COUNT(cliente_id) cuenta filas donde cliente_id no es NULL. Resultado: 7 (porque hay una fila con cliente_id = NULL).
Tip: usar COUNT(*) cuando quieres número de filas; COUNT(col) cuando quieres contar valores presentes; COUNT(DISTINCT ...) para cardinalidad.
2) SUM() — sumar cantidades / montos
Descripción rápida: suma valores numéricos, muy usado para ingresos, cantidades y métricas agregadas.
Ejemplo simple — ingresos totales
Resultado en el dataset: 2,930.
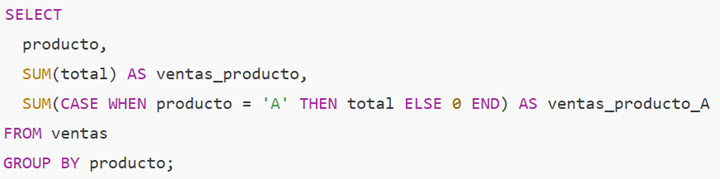
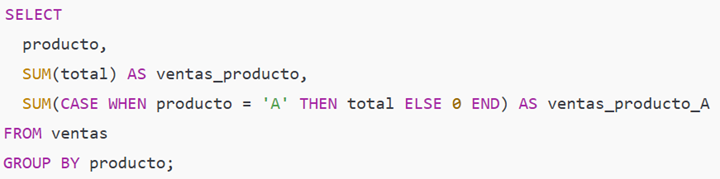
Ejemplo intermedio — suma condicional por producto (agregación condicional)
Paso a paso:
SUM(total) por producto suma el total de cada producto.
La expresión SUM(CASE WHEN producto = 'A' THEN total ELSE 0 END) suma sólo donde el producto es A.
Sirve para comparar totales por categoría y para métricas segmentadas en una sola pasada.
Tip: para condicionales dentro de agregaciones, usa CASE (compatibilidad máxima).
3) AVG() — promedio (mean)
Descripción rápida: calcula promedio aritmético. Atención a la precisión y al tratamiento de NULL.
Ejemplo simple — promedio de total
Cálculo con el dataset: suma total 2,930 ÷ 8 filas = 366.25.
Ejemplo intermedio — promedio ponderado (precio promedio ponderado por cantidad) para producto A
NULLIF(SUM(cantidad), 0) evita división por cero si no hay ventas.
Tip: en bases donde la división de enteros trunca, CAST(... AS DECIMAL) es necesario para obtener decimales. En el ejemplo anterior puede ser buena idea castear si su SGBD hace división entera.
4) MIN() — mínimo
Descripción rápida: devuelve el menor valor de una columna (fechas, números, strings según contexto).
Ejemplo simple — fecha de la venta más temprana
Resultado: 2024-11-30 (fila 7).
Ejemplo intermedio — primera venta por producto
Uso: útil para saber el inicio de ventas por línea, cohortes, etc.
5) MAX() — máximo
Descripción rápida: devuelve el mayor valor; muy usado para encontrar picos, máximo ticket, etc.
Ejemplo simple — venta más alta (monto)
Resultado: 1000 (fila 8).
Ejemplo intermedio — máximo por región y quién la hizo (uso combinado con JOIN o subconsulta)
Paso a paso: agrupa por region y calcula el mayor total por cada una.
6) CASE WHEN ... THEN ... END — expresiones condicionales
Descripción rápida: categoriza o crea nuevas variables basadas en condiciones.
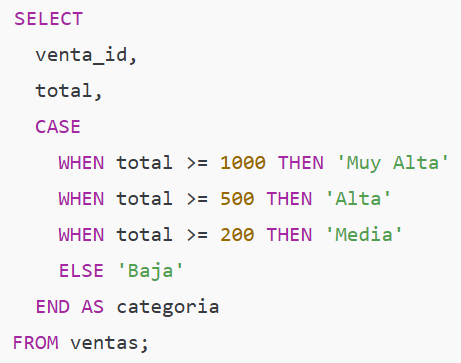
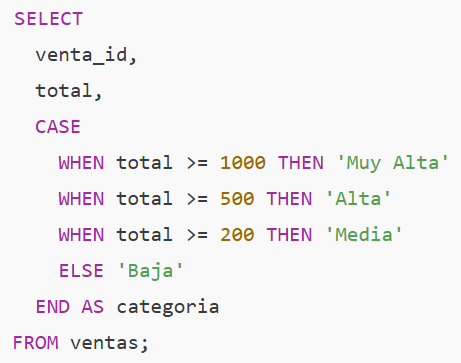
Ejemplo simple — categorizar ventas por tamaño
Aplicación (con nuestros totales):
1000 → 'Muy Alta'
500 → 'Alta'
300 → 'Media'
120 → 'Baja', etc.
Ejemplo intermedio — métricas por segmento en una sola consulta
Beneficio: crear “buckets” y agregaciones en la misma pasada.
7) COALESCE() — manejo de NULL
Descripción rápida: devuelve el primer valor no nulo entre sus argumentos. Muy útil para normalizar datos faltantes.
Ejemplo simple — reemplazar NULL de cliente por "Desconocido" (o un código)
Resultado: la fila con cliente_id = NULL mostrará -1.
Ejemplo intermedio — sumar valores evitando NULL
Por qué: SUM(NULL) ignora NULL, pero con columnas mixtas o cálculos intermedios COALESCE evita errores en expresiones personalizadas.
Tip: usa COALESCE en SELECT, JOIN y GROUP BY cuando quieras tratar NULL como un valor por defecto.
8) CAST() — conversión de tipos (y CONVERT en algunos SGBD)
Descripción rápida: convierte entre tipos (string → fecha, entero → decimal, etc.). Crucial para cálculos correctos y formateos.
Ejemplo simple — asegurar decimales en una división
Paso a paso: CAST(SUM(total) AS DECIMAL(10,2)) garantiza que la división produzca decimal (dependiendo del SGBD).
Ejemplo intermedio — convertir texto a fecha (cuando la columna es string)
Uso real: limpieza ETL cuando recibes fechas o números como texto.
Tip: siempre conoce el tipo de dato de tus columnas; las conversiones mal hechas provocan errores o truncamiento.
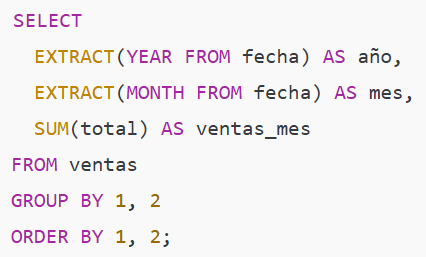
9) EXTRACT() — extraer partes de fechas (año, mes, día)
Descripción rápida: extrae componentes de tipos fecha/hora. Útil para series temporales, cohortes y agregaciones por periodos.
Ejemplo simple — ventas por año
En nuestro dataset: aparecen ventas en 2024 y 2025; EXTRACT agrupa correctamente.
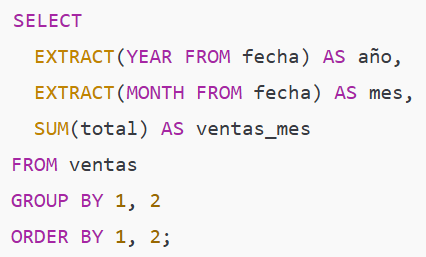
Ejemplo intermedio — ventas por año y mes (series mensuales)
Qué obtienes: una tabla año/mes con totales, lista para series temporales o visualizaciones.
Tip: si tu SGBD soporta DATE_TRUNC('month', fecha) (ej. Postgres), esa función devuelve directamente la fecha truncada al primer día del mes y es cómoda para agrupar.
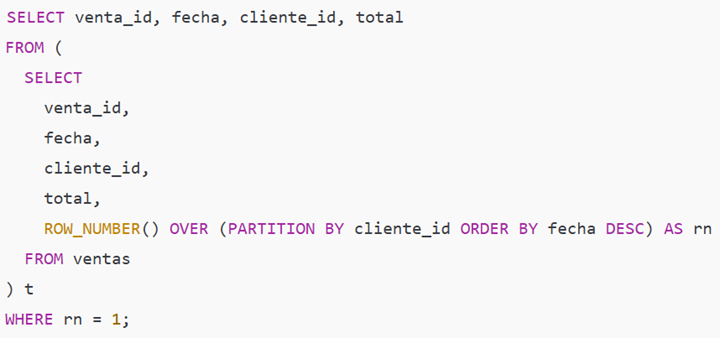
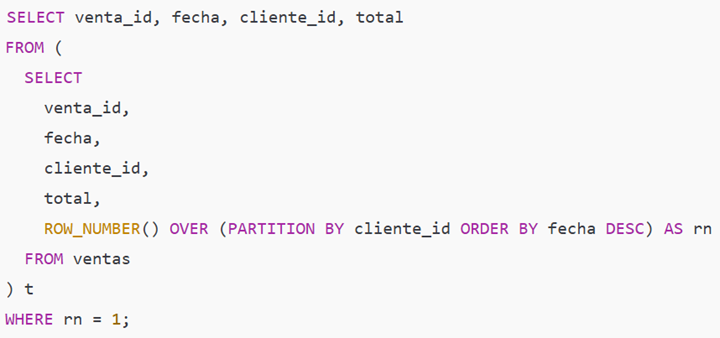
10) ROW_NUMBER() (función ventana) — particionar y ordenar dentro de grupos
Descripción rápida: asigna un número incremental dentro de particiones; fundamental para "top N por grupo", deduplicación por la fila más reciente, etc.
Ejemplo simple — obtener la última venta por cliente (deduplicación)
Paso a paso con datos:
Para cada cliente_id, ROW_NUMBER() ordena sus ventas por fecha DESC.
rn = 1 toma la venta más reciente de cada cliente.
Resultado: una fila por cliente con su última compra. Si cliente_id es NULL, se trata como su propia partición (depende del SGBD).
Ejemplo intermedio — Top 3 productos por región según ventas totales
Qué pasa aquí:
El GROUP BY region, producto calcula ventas por producto/región.
ROW_NUMBER() OVER (PARTITION BY region ORDER BY SUM(total) DESC) asigna ranking dentro de cada región.
Filtrando rn <= 3 obtenemos top 3 por región.
Tip: también existen RANK() y DENSE_RANK() si quieres manejar empates de forma distinta.
Buenas prácticas
NULLs: siempre piensa cómo quieres tratarlos. COUNT(col) y COALESCE suelen ser claves.
División / precisión: para porcentajes o promedios, CAST/CONVERT evitan truncamientos por división entera en algunos SGBD.
WHERE vs HAVING: WHERE filtra filas antes de agregación; HAVING filtra grupos después de GROUP BY.
Funciones en columnas indexadas: evita aplicar funciones (p. ej. CAST, LOWER, DATE()) en columnas usadas por índices en condiciones WHERE, porque puede impedir el uso del índice.
Window vs Aggregation: para top-N o cálculos que necesitan contexto (porcentaje sobre total, running total), las funciones ventana (ROW_NUMBER(), SUM() OVER(), ...) son más eficientes y expresivas.
Legibilidad: usa alias claros, comenta CASE complejos y divide consultas grandes en CTEs (WITH) para facilitar mantenimiento.
Performance: para datasets grandes, comprueba planes de ejecución y considera índices, particiones o pre-aggregaciones.
Resumen rápido
Como viste, las funciones de SQL son herramientas esenciales para transformar datos en información útil. Con solo unas cuantas líneas de código puedes contar, agrupar, calcular promedios, comparar valores o generar métricas personalizadas que te ayuden a responder preguntas de negocio o descubrir tendencias en tus datos.
Dominar estas funciones no solo te hará más eficiente en tus consultas, sino que también te acercará al siguiente nivel del análisis de datos: crear reportes, paneles e indicadores que realmente aporten valor. Recuerda practicar con tus propios datasets y combinar varias funciones en una misma consulta para seguir desarrollando tu pensamiento analítico en SQL.